Creating Wordfeud logs from images
There is a popular mobile game in Denmark called Wordfeud. It is basically a Scrabble clone with slightly different scorings and dictionary. I enjoy playing it and I have logged about 200 games as of writing this. Frankly, that is not a lot as I occasionally see players with 10000+ plus (not a typo). Still, I really wanted to do some Wordfeud statistics and the only sample pool is my own.

A screenshot from Wordfeud with some blank space removed (yes I lost).
The question is, how do I retrieve my Wordfeud game data to save for later analysis? The game has no API, you cannot request your data and I don’t feel like booting up an android emulator and twiddle with the memory (if that is even possible) every time I finish a game, since completed games are only shown for about 3 days.
Thankfully, 2021 me thought of this and starting taking a screenshot of every completed Wordfeud game. Fast forward to about a month ago, when I succeeded in using template matching and an OCR algorithm to turn an image, such as the one above, to the log shown below. This will severely ease analysis of my Wordfeud games in the future.
|
|
Notice that the log contains the date, derived from a filename, the player names, their scores and the board. The opponent’s rack can easily be derived as long as no tiles remain in the bag which is more often than not the case in Wordfeud (and Scrabble).
 Update from the future
Update from the future
Detecting name and points
From Wikipedia:
Optical character recognition (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text
In other words, OCR turns images of text into actual text. I use the most popular open source OCR library Tesseract in order to scan the names of the opponent and both of our scores.
The locations of names and points never change so I can easily crop the image to the correct dimensions and perform the OCR which works (almost) flawlessly.
Flaws include emojis turning into odd characters (like Andreas @ in the log above where @ is a wizard emoji 🧙) and inserting newlines at the end of names.
I could almost end here, as I can just do the same for each letter, no? No. These OCR libraries are large neural networks trained on billions of coherent letters, i.e. words and have a hard time determining just a single letter. Furthermore, using OCR for a single letter which is (nearly) identical every time is like cracking a walnut with a sledgehammer. Also, I want a challenge :)
Matching tiles
Quoting Wikipedia again because I am lazy:
Template matching is a technique in digital image processing for finding small parts of an image which match a template image.
Esentially, we can take an expected image, the template, and slide it over the another image and perform some operation on each pixel of the overlayed image. Based on the results of these operations we decide if we have found our template.
I have tried to showcase this below on The Black Parade below, where we are trying to match the skeleton on the album cover. An exact copy of the skeleton is slid across the image and for each pixel the difference is taken. This means that if the template and the image has matching pixels, they cancel out and produce black. If they have differing pixels they produce white. The best match in this case is where the difference has the most amount of black pixels, i.e. at the location of the skeleton.
Visualisation of template matching. Credit me.
In reality, every single pixel is scanned and a heatmap is generated from the template matching function. This heatmap is used to determine where the upper left corner of the template is most likely to reside. Instead of using the difference I use the correlation coefficient which I calculate using OpenCV.

Process of detecting a letter within the image of a Wordfeud tile.
Notice that I reduce every image to a two bit image (black and white, no grays) to simplify processing. I then crop every possible letter and form an alphabet of templates.

Every letter in Danish Wordfeud, cropped.
I know where every tile is, and I don’t really need template matching to figure out where the letter is within the tile. I only use template matching to determine the best correlation between image and template, which is ranked against the other letters’ best correlation. This means I can just take a picture of every tile, match against my alphabet and choose the letter with the highest correlation, right?
The problem of ÅL
I made a heatmap to determine if my tiles match correctly. As expected, each letter produces a large correlation when matched with themselves. This is seen on the diagonal. We can also see that O is close to Ø and vice versa, but the stronger correlation is the correct one, so no worries there.
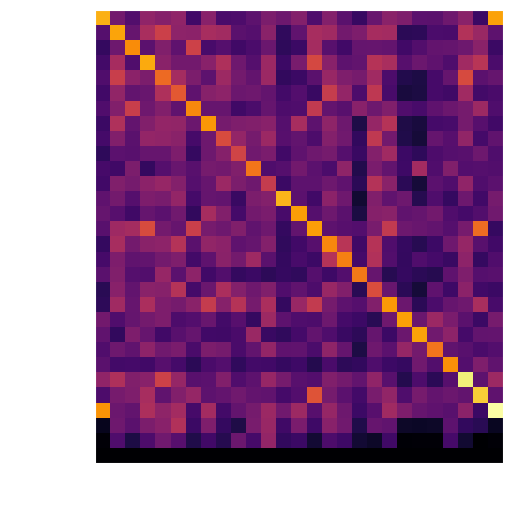
Heatmap of the correlation between board tile and matching (template) tile. The brighter the value, the greater the correlation.
It appears that Å matches Å but that Å also matches A. This is actually because of the fact that each letter is cropped completely. Simply put, Å is just an A with more pixels to match. If A is slightly different (due to screen aliasing or scaling), then Å might be a better match, since the remaining pixels don’t matter.
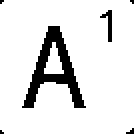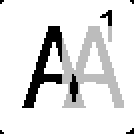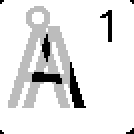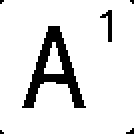
Sliding Å onto A is like sliding A onto A just with excess black.
This is fixed by adding white margin to all templates. This causes A to be correct as the white pixels above it must also match. This also fixes another odd issue as L keeps matching on blank tiles. This is for the exact same reason

An L without margins matches the corner of a blank quite nicely.
Blank, wild and rack tiles
To determine if a tile is blank, we set a threshold for the correlation coefficient. If it is too low, no letter is present. I find this threshold by matching every alphabet tile to every other tile, including a blank. As expected, the blank matches very poorly even in the best case.
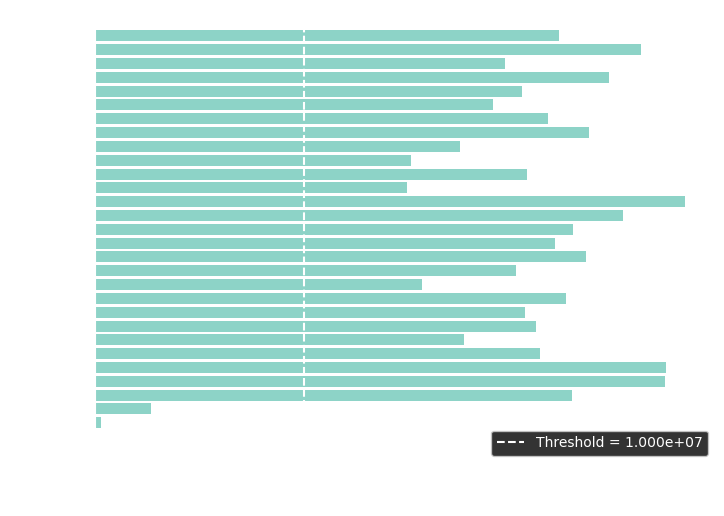
Maximum correlation between any alphabet tile and any tile (including blanks).
Wildcards, in Wordfeud and in Scrabble, substitute any one letter and awards zero points. It is important to track the wildcard. On the rack, the wildcard appears as a blank but on the board it shows the chosen substitute letter, but without any points. To detect if a tile is blank, we detect if the upper right corner of the matches any of 6 point templates. Similarly, a threshold is found.
Lastly, the tiles on the rack are determined by matching with the exact same templates but scaled. This works quite well, as long as the correct scale factor is found.
Conclusion
The software works very well as it correctly tracks in rack, board, names and scores. I manually checked about 100 scanned boards, and not one was wrong. I decided to save the result in JSON format as it is decently human-readable and easy to read for a machine for later analysis. The board also includes a star “*” next to the wildcard, which does sadly mess up the readability a bit. I created a script which watches a folder and extracts the logs from any new pictures within. The script looks like this while running:
Watch: 15%|█▍ | 17/116 [01:46<10:22, 6.29s/it, creating=log\Screenshot_20210427-192712_Wordfeud.json]
I’ll leave you with another one of my logs:
|
|
Published 6. September 2023
Last modified 9. September 2023